자체적으로 데이터 군집을 나누는 알고리즘
데이터 세분화로 군집별 유사성 파악하기
[월드투데이 김새민 기자] 고객 맞춤형 서비스가 대두되면서 고객을 세분화하여 관리하는 것이 중요해졌다. 데이터 분석으로 군집별 특징을 파악한다면, 고객의 니즈에 한 걸음 더 다가갈 수 있다.
모든 고객을 똑같은 방법으로 관리한다면 이탈하는 고객이 생길 것이다. 고객 유형에 맞는 홍보 문구를 기획하고, 소비 패턴에 따라 다른 혜택을 제공하여 여러 유형의 고객들을 사로잡아야 한다.
우리는 쉽게 사람들을 MBTI나 혈액형으로 나눈다. 정해진 틀 안에서 사람들을 구분하기는 쉽다. 그렇지만 명확한 기준이 없다면? 수많은 사람을 분류하는 것은 어려운 일이다.
고려 사항은 많은데 분류 기준이 없을 때 클러스터링을 활용할 수 있다. 클러스터링은 데이터의 특성을 바탕으로 자체적으로 군집을 나눈다. 형성된 군집별로 특성을 분석하면 고객을 유형에 따라 설명할 수 있다.
클러스터링
클러스터링은 유사한 속성들을 갖는 관측치들을 묶어 전체 데이터를 군집으로 나눈다. 데이터를 분류하기 위한 기준이 존재하지 않을 때, 유사한 데이터를 묶어 볼 수 있는 것이 장점이다. 데이터의 크기가 크고 변수가 많아 눈으로 보는 것으로는 데이터를 세분화하기 어려울 때 유용하다.
기준을 설정할 필요가 없는 기법이지만, 클러스터링에 앞서 고려해야 할 사항이 있다. 바로 데이터의 변수를 파악하는 것이다.
1. 유사한 변수는 하나만
2. 불필요한 변수는 사전에 제외
모든 변수를 활용하는 것이 아니다. 유사한 변수는 하나만 이용하면 된다. '나이'와 '생년월일' 정보는 둘 다 나이를 함축하므로 '나이' 변수 하나만 이용한다.
고객들의 성격을 군집별로 파악하고 싶다고 할 때, 관점에 따라 '가입경로'는 고객의 가입 이후 패턴을 설명하기에 적절하지 않을 수 있다. 불필요한 변수가 군집화에 영향을 끼치는 것을 미연에 방지하기 위해 해당 변수는 군집 형성 이전에 제외한다.
클러스터링 알고리즘 종류
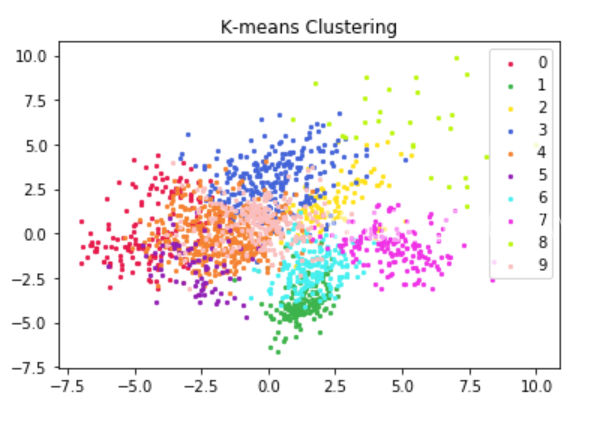
◆ K-means
대표적인 클러스터링 기법으로 ‘특정 데이터의 특성을 갖는 값이 중심에 위치할 것이다.‘를 전제로 한다. 특정 유저 군집을 대표하는 유저가 중심에 위치하고, 대표 유저와 변이를 보이는 유저들이 주변에 위치한다는 가정하에 진행한다.
㉠ K개의 중심을 임의로 생성 → ㉡ 유클리디안 거리를 기반으로 가까운 중심에 모든 관측치 군집 할당 → ㉢ 각 Cluster의 중심을 다시 계산 → 중심이 변하지 않을 때까지 위의 ㉡~㉢의 과정을 반복
K개 만큼의 군집이 생기며, 군집 개수 설정에 따라 결과도 달라져서 적절한 K값을 설정하는 것이 중요하다. 각 군집 중심의 초깃값을 랜덤하게 정하면서, 초깃값 위치에 따라 결과가 달라진다.
k-means는 클러스터의 대푯값을 평균으로 구하여 분산을 기준으로 군집화한다. 평균값을 구하는 연산을 수행하여 이상치에 민감하다. 이를 방지하고자 클러스터의 대푯값을 중앙값으로 결정하는 k-medoid 알고리듬이 존재한다.
◆ DBSCAN
데이터의 밀도를 활용해 일정 밀도 이상을 가진 데이터를 기준으로 군집을 형성하는 방법이다. 군집의 개수 k를 미리 설정하는 대신에 한 군집 내에 최소 몇 개(n개)의 데이터가 있어야 하는지와 반경(x)을 사전에 정의해야 한다. 특정 점을 기준으로 반경 x 내에 점이 n개 이상 있으면 하나의 군집으로 인식한다.
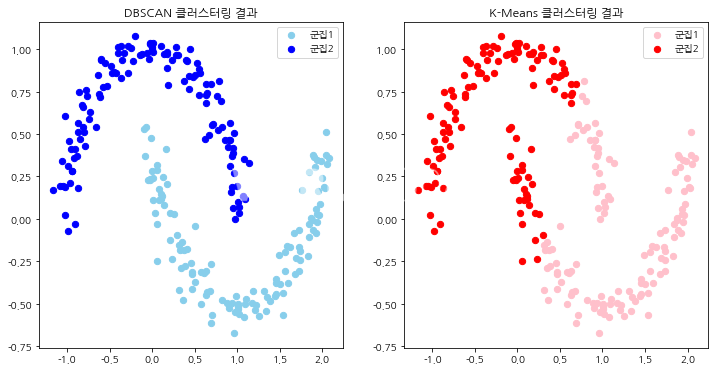
K-Means와 비교해보면, DBSCAN은 선으로 나눌 수 없는 데이터의 경계를 파악하는 데 유리하다. 이상치에도 강하다. 밀도 분포가 낮은 곳에 있는 데이터는 하나의 군집으로 인식하지 않고 이상치로 파악한다. 모든 데이터를 군집에 할당하는 것이 아니라 다른 데이터와 동떨어진 데이터는 배제한다.
단, 배제되는 데이터가 몇 개가 될지는 알 수 없고, 특성을 설명할 수 있는 데이터마저 군집화에서 제외할 수도 있어 유의해야 한다.
◆ AGNES
계층적 클러스터링의 하나이다. 가장 유사한 개체를 묶어 나가는 과정을 반복하여 원하는 개수의 군집을 형성한다. AGNES는 개별 데이터 하나하나를 하나의 독립적인 클러스터로 가정하고, 가장 유사도가 높거나 거리가 가까운 군집 두 개를 하나로 합치면서 군집 개수를 줄여 가는 방법을 말한다. 각 클러스터의 거리를 측정하는 방법에 따라 최장 연결, 최단 연결 등으로 구분한다.
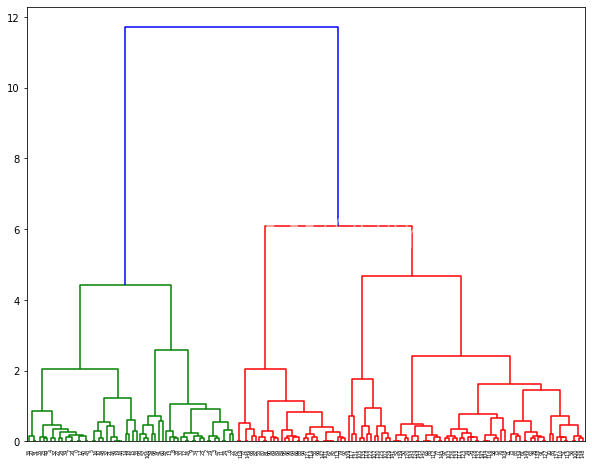
목표 클러스터 개수 지점에서 계층을 잘라 군집을 도출한다. 변수가 많거나 데이터의 크기가 클수록 계산량이 많아져 속도가 느려진다.
클러스터링은 기준 없이도 데이터를 자동으로 세분화한다는 것이 장점이다. 그렇지만 세분화된 데이터에서 군집별 특성을 파악하는 것은 분석자의 몫이다.
세분화된 데이터를 활용하기 위해서는 군집별로 특성이 명확하게 드러나는지 확인할 필요가 있다. 유사도 측정 방법과 군집 수, 클러스터링 기법에 따라 결과는 달라진다. 다양한 방법으로 클러스터링을 시도하면서 형성된 군집이 의미가 있는지 검토해야 한다.